https://www.ben-evans.com/benedictevans/2026/2/19/how-will-openai-compete-nkg2x
“Jakub and Mark set the research direction for the long run. Then after months of work, something incredible emerges and I get a researcher pinging me saying: “I have something pretty cool. How are you going to use it in chat? How are you going to use it for our enterprise products?”
“You've got to start with the customer experience and work backwards to the technology. You can't start with the technology and try to figure out where you're going to try to sell it”
It seems to me that OpenAI has four fundamental strategic questions.
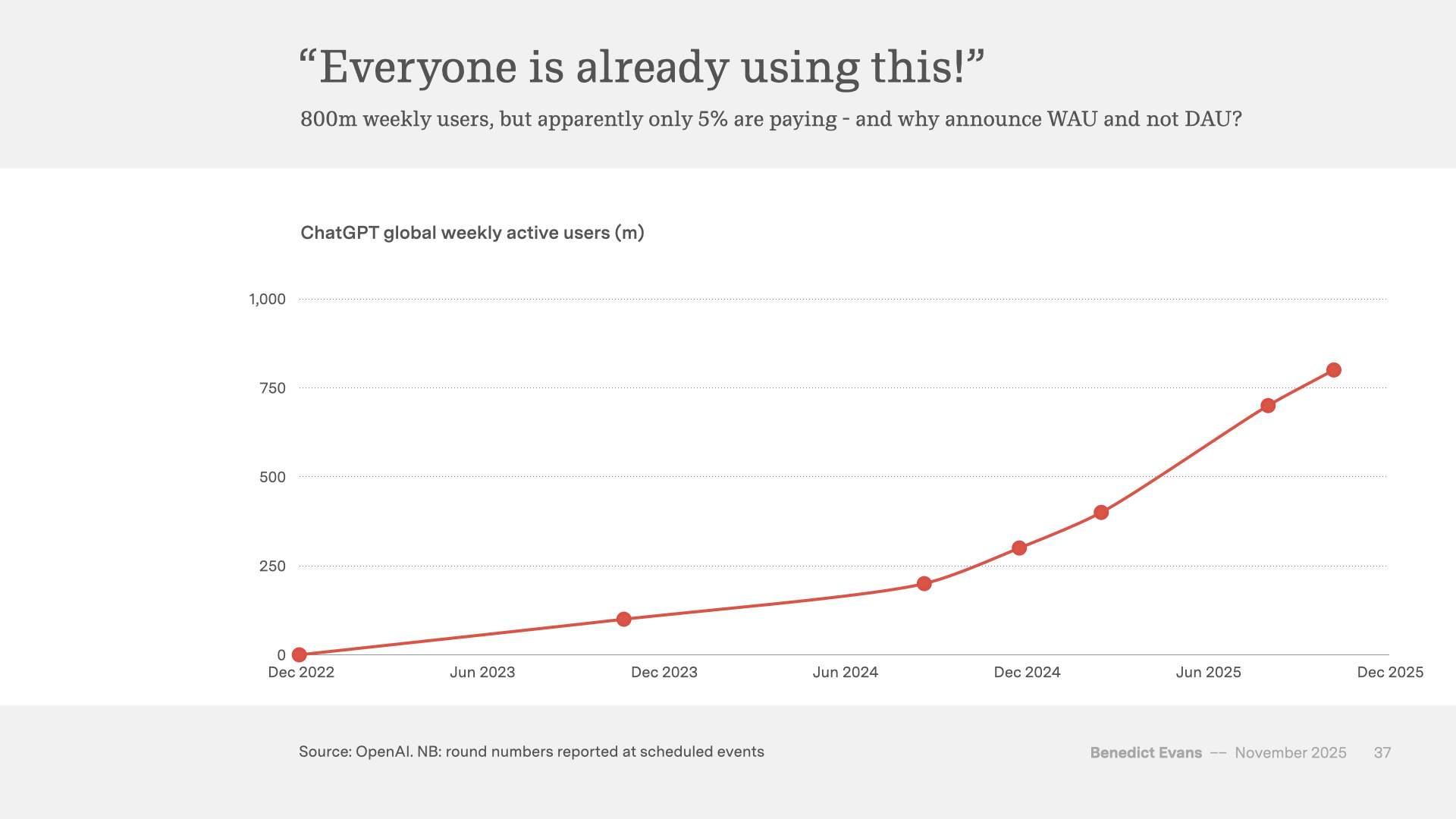
First, the business as we see it today doesn’t have a strong, clear competitive lead. It doesn’t have a unique technology or product. The models have a very large user base, but very narrow engagement and stickiness, and no network effect or any other winner-takes-all effect so far that provides a clear path to turning that user base into something broader and durable. Nor does OpenAI have consumer products on top of the models themselves that have product-market fit.
Second, the experience, product, value capture and strategic leverage in AI will all change an enormous amount in the next couple of years as the market develops. Big aggressive incumbents and thousands of entrepreneurs are trying to create new features, experiences and business models, and in the process try to turn foundation models themselves into commodity infrastructure sold at marginal cost. Having kicked off the LLM boom, OpenAI now has to invent a whole other set of new things as well, or at least fend off, co-opt and absorb the thousands of other people who are trying to do that.
Third, while much of this applies to everyone else in the field as well, OpenAI, like Anthropic, has to ‘cross the chasm’ across the ‘messy middle’ (insert your favourite startup book title here) without existing products that can act as distribution and make all of this a feature, and to compete in the most capital-intensive industry in history without cashflows for existing businesses to lean on. Of course, companies that do have all of that need to be able to disrupt themselves, but we’re well past the point that people said Google couldn’t do AI.
The fourth problem is expressed in the quotes I used above. Mike Krieger and Kevin Weil made similar points last year: when you’re head of product at an AI lab, you don’t control your roadmap. You have very limited ability to set product strategy. You open your email in the morning and discover that the labs have worked something out, and your job is to turn that into a button. The strategy happens somewhere else. But where?
OpenAI does still at least arguably set the agenda for new models, and it has a lot of great technology and a lot of clever and ambitious people. But unlike Google in the 2000s or Apple in the 2010s, those people don’t have a thing that really really works already that no-one else can do. I think that one way you could see OpenAI’s activity in the last 12 months is that Sam Altman is deeply aware of this, and is trying above all to trade his paper for more durable strategic positions before the music stops.
Let’s start with the models.
View fullsize
There are many benchmarks, all of them ‘wrong’, but they all show the same picture
There are something like half a dozen organisations that are currently shipping competitive frontier models, all with pretty-much equivalent capabilities. Every few weeks they leapfrog each other. There is variation within those capabilities, it’s possible to drop off the curve (Meta, for now) or fail to get onto it (Apple, Amazon, Microsoft, for now), or remain six months behind the frontier (China), or rely heavily on other people’s work (China, again) and all of this needs a lot of money (of which more below), but today there is no mechanic we know of for one company to get a lead that others in the field could never match. There is no equivalent of the network effects seen at everything from Windows to Google Search to iOS to Instagram, where market share was self-reinforcing and no amount of money and effort was enough for someone else to to break in or catch up.
This could change if there was a breakthrough that enabled a network effect, most obviously continuous learning, but we can’t plan for that happening. It could also change if there are practical scale effects around access to proprietary data, which today is the dark matter of AI: this could be user data (but it’s not clear what scale here would look like, and the existing platform companies have a lot), or vertical data (foundation models don’t know what happens inside SAP or Salesforce and don’t have millions of spreadsheets from inside investment banks, though you can sometimes buy this or pay people to make it, but so can all the other big players). There might be something else here as well, but at the moment we don’t know and you can’t plan for it, so we have to presume that the models will remain very close for the time being.
View fullsize